2025. 2. 3. 02:28ㆍ_Project/DeepSeek_블로그자동화
25.02.02
2. 일단 깃허브로 들어가


https://github.com/deepseek-ai/DeepSeek-V3
일단 무지몽매하지만 깃허브로 들어왔다. README를 읽어봐준다. 아무래도 모델이 다양해보인다. 나는 다음과 같은 모델이 필요하니 필요한 모델 추천부터 받아보려 요구사항 명세를 시작해본다. Chat GPT와 함께,,,
너는 AI엔지니어야. 나는 딥시크라는 오픈소스 AI를 이용해서, 모델을 생성하려고해. 아래의 요구사항을 진행하려면 어떤 모델을 사용해야할까? 추천부탁해
1. 네이버 블로그, 티스토리, 벨로그와 같은 다양한 플랫폼의 글을 학습합니다.
2. 학습과정에서는 다량의 문자열또는 Markdown 을 파일로 학습합니다.
2. 특정 사람의 어투를 최대한 흉내내거나 동일하게 합니다.
3. 특정 주제를 입력받고 주제글을 어투를 적용하여 작성합니다.
----
1. 다양한 플랫폼의 데이터 학습
DeepSeek-V3는 14.8조 개의 다양한 고품질 토큰을 학습한 모델입니다. 이 토큰에는 Naver Blog, Tistory, Velog와 같은 다양한 블로그 플랫폼에서 작성된 데이터가 포함될 수 있습니다. 이를 통해 DeepSeek-V3는 다양한 형식의 텍스트를 처리할 수 있어 블로그 글 작성, 댓글, 포스트 등의 자연어 처리에 매우 유용합니다.
2. Markdown 또는 텍스트 파일 학습 가능
Markdown은 블로그 글 작성 시 많이 사용되는 텍스트 형식입니다. DeepSeek-V3는 Markdown 형식의 데이터를 처리할 수 있어, Markdown 형식의 글을 그대로 모델에 제공해도 효과적으로 학습할 수 있습니다. 이러한 구조화된 텍스트를 잘 처리하는 모델로, 블로그 콘텐츠와 같은 복잡한 텍스트 형식을 다루는 데 유리합니다.
3. 특정 개인의 말투와 스타일 모방 가능
DeepSeek-V3는 Multi-Token Prediction(MTP)이라는 기능을 포함하고 있어, 특정 사람의 말투나 글 스타일을 학습하고 모방하는 데 뛰어납니다. 예를 들어, 특정 블로거나 작가의 글 스타일을 모델에 학습시키면, 그 사람처럼 글을 작성할 수 있는 능력을 얻을 수 있습니다. 이는 일관된 톤과 스타일로 글을 생성해야 하는 블로그 운영자에게 유리합니다.
4. 특정 주제와 톤에 맞는 콘텐츠 생성
DeepSeek-V3는 복잡한 프롬프트를 처리하고 특정 톤과 주제에 맞는 글을 생성할 수 있는 능력이 뛰어납니다. 예를 들어, 특정 주제에 대해 전문가처럼 글을 쓰거나, 친근한 톤으로 블로그 글을 작성하는 것이 가능합니다. 이는 주제에 맞는 일관된 콘텐츠를 빠르게 생성할 수 있도록 도와줍니다.
결론
DeepSeek-V3는 블로그 글 작성에 필요한 여러 조건을 만족하는 모델입니다. 다양한 플랫폼의 데이터를 처리할 수 있으며, Markdown 형식으로 작성된 글을 학습하고, 특정 사람의 스타일을 모방하여 콘텐츠를 생성할 수 있습니다. 이러한 특성 덕분에 자연어처리와 글 생성기 분야에서 매우 유용하게 사용될 수 있습니다.
이 모델을 활용하면 개발자도 블로그 글을 자동으로 생성하거나, 개인화된 콘텐츠를 생성하는 데 큰 도움이 될 것입니다.
----
DeepSeek README를 ChatGPT에 학습시켜 분석 및 어떤 모델에 적합한지 왜 사용해야하는지를 잘 정리했다. DeepSeek-V3은 Markdown형식의 효율적인 학습과 스타일 맞춤형 글 생성이 가능하여 콘텐츠 생성과 데이터 처리에 적합한 Mixture-of-Experts(MoE)모델이라고 한다. 사실일까?
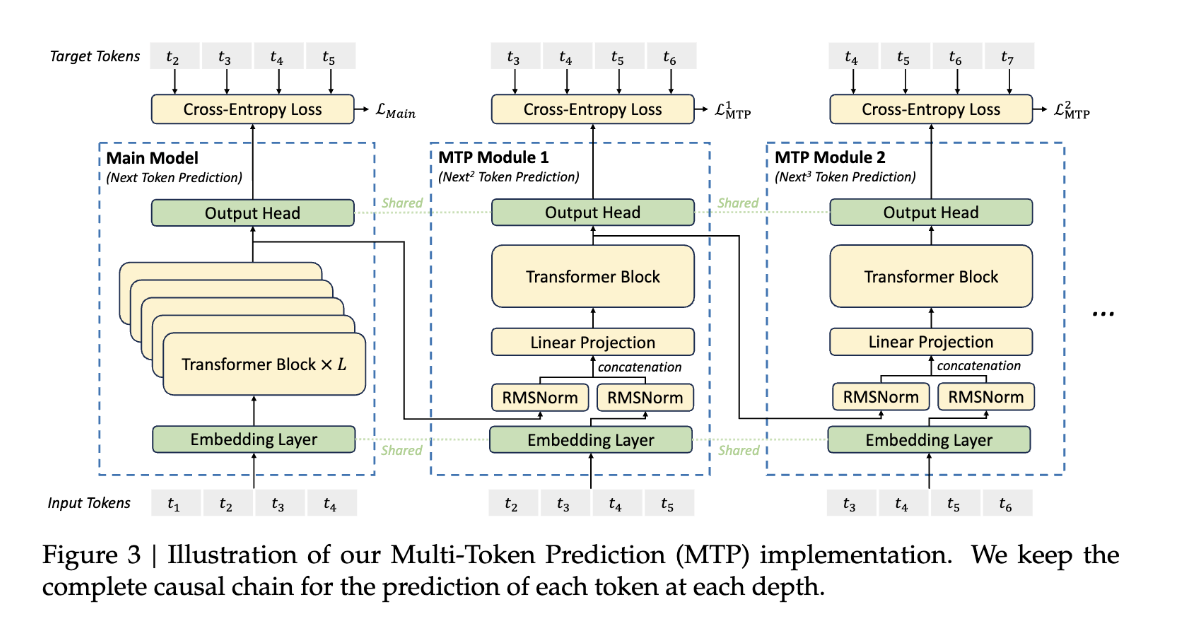
> MTP(Multi-Token Prediction)다중토큰예측은 개발 중에 있으며, 한 번에 여러개의 토큰을 예측하는 기술이다. 이를 사용하면 자연어처리 모델이 주어진 문맥을 바탕으로 여러개 토큰을 동시에 예측하여 택스트 생성이 가능하게 한다.
> For developers looking to dive deeper, we recommend exploring README_WEIGHTS.md for details on the Main Model weights and the Multi-Token Prediction (MTP) Modules. Please note that MTP support is currently under active development within the community, and we welcome your contributions and feedback.
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/README_WEIGHTS.md
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/DeepSeek_V3.pdf
깃허브를 돌아다녀보며, 알아낸 것은 딥시크는 Chat GPT와 유사한 트랜스포머 모델을 사용하고 있었다. (GPT: Generative Pre-trained Transformer) 텍스트를 이해하고 생성하는데 특화되어 있는 자기 회귀 모델로 다음 단어를 예측하고 생성하는 모델이다. 어쩌다보니 53p 논문이 작성되어 있는데 읽어보자.
정리해보면 주요 사항은 다음과 같다.
- 고비용 텐서 처리를 하지 않아도 훈련이 가능 (전체 훈련 비용을 557만 달러, 2개월 이내 전체 학습)
- H800 GPU의 대여 비용이 시간당 $2일 경우, 전체 훈련 비용은 단 $5.576M에 불과
- GPT-3 훈련에 100M GPU시간이 소요되었으니 200M이상인 경우 90%이상 절감 예상
- 코드와 수학 처리에 강함
한국어 번역본 (chat GPT)
서론
최근 몇 년 동안, 대형 언어 모델(Large Language Models, LLMs)은 빠르게 발전하고 있으며 (Anthropic, 2024; Google, 2024; OpenAI, 2024a), 인공지능 일반화(AGI)와의 격차를 점차적으로 줄여가고 있습니다. 폐쇄형 모델 외에도, DeepSeek 시리즈(DeepSeek-AI, 2024a,b,c; Guo et al., 2024), LLaMA 시리즈(AI@Meta, 2024a,b; Touvron et al., 2023a,b), Qwen 시리즈(Qwen, 2023, 2024a,b), Mistral 시리즈(Jiang et al., 2023; Mistral, 2024) 등 오픈소스 모델들도 중요한 진전을 이루어, 폐쇄형 모델들과의 격차를 줄이기 위해 노력하고 있습니다. 오픈소스 모델의 성능 한계를 더욱 확장하기 위해, 우리는 모델을 확장하고 671B 파라미터를 가진 대형 혼합 전문가(Mixture-of-Experts, MoE) 모델인 DeepSeek-V3를 소개합니다. 이 모델에서는 각 토큰에 대해 37B가 활성화됩니다.
미래 지향적인 관점에서 우리는 지속적으로 강력한 모델 성능과 경제적인 비용을 추구하고 있습니다. 따라서, DeepSeek-V3는 아키텍처 측면에서 여전히 효율적인 추론을 위한 Multi-head Latent Attention (MLA) (DeepSeek-AI, 2024c)과 비용 효율적인 훈련을 위한 DeepSeekMoE (Dai et al., 2024)를 채택하고 있습니다. 이 두 가지 아키텍처는 DeepSeek-V2(DeepSeek-AI, 2024c)에서 검증되어, 효율적인 훈련과 추론을 유지하면서 강력한 모델 성능을 유지할 수 있음을 입증했습니다. 기본 아키텍처 외에도, 우리는 모델 성능을 추가적으로 향상시키기 위한 두 가지 전략을 구현했습니다. 첫째, DeepSeek-V3는 로드 밸런싱의 부정적인 영향을 최소화하기 위해 보조 손실 없는 전략(Wang et al., 2024a)을 선도적으로 채택했습니다. 둘째, DeepSeek-V3는 다중 토큰 예측 훈련 목표를 사용하여, 평가 기준에서 전반적인 성능 향상을 관찰했습니다.
효율적인 훈련을 달성하기 위해, 우리는 FP8 혼합 정밀 훈련을 지원하고 훈련 프레임워크에 대한 종합적인 최적화를 구현했습니다. 저정밀 훈련은 효율적인 훈련을 위한 유망한 해결책으로 떠오르고 있으며 (Dettmers et al., 2022; Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b), 그 발전은 하드웨어 성능 향상과 밀접하게 연관되어 있습니다 (Luo et al., 2024; Micikevicius et al., 2022; Rouhani et al., 2023a). 이 작업에서 우리는 FP8 혼합 정밀 훈련 프레임워크를 도입하고, 그 효과를 대규모 모델에서 처음으로 검증했습니다. FP8 계산 및 저장을 지원함으로써 우리는 훈련을 가속화하고 GPU 메모리 사용을 줄일 수 있었습니다. 훈련 프레임워크 측면에서는 DualPipe 알고리즘을 설계하여 효율적인 파이프라인 병렬 처리를 구현했으며, 훈련 중 계산과 통신의 겹침을 통해 대부분의 통신을 숨길 수 있었습니다. 이 겹침은 모델이 더욱 확장될수록, 계산과 통신 비율을 일정하게 유지하는 한, 우리는 노드 간의 미세한 전문가들을 사용할 수 있고, 거의 제로에 가까운 전노드 간 통신 오버헤드를 달성할 수 있습니다. 또한, 우리는 InfiniBand(IB)와 NVLink 대역폭을 완전히 활용할 수 있도록 효율적인 교차 노드 전노드 간 통신 커널을 개발했습니다. 더 나아가, 메모리 풋프린트를 세심하게 최적화하여, 고비용 텐서 병렬 처리를 사용하지 않고도 DeepSeek-V3를 훈련할 수 있었습니다. 이러한 노력을 결합하여 우리는 높은 훈련 효율성을 달성했습니다.
프리트레이닝 동안, 우리는 14.8T의 고품질이고 다양한 토큰을 사용하여 DeepSeek-V3를 훈련했습니다. 프리트레이닝 과정은 매우 안정적이었습니다. 전체 훈련 과정에서 복구 불가능한 손실 스파이크가 발생하거나 롤백을 해야 했던 일은 없었습니다. 이후, 우리는 DeepSeek-V3의 컨텍스트 길이를 두 단계로 확장했습니다. 첫 번째 단계에서는 최대 컨텍스트 길이를 32K로 확장하고, 두 번째 단계에서는 이를 128K로 추가 확장했습니다. 그 후, 우리는 Supervised Fine-Tuning (SFT) 및 **Reinforcement Learning (RL)**을 사용하여 DeepSeek-V3의 기본 모델에 대해 인간의 선호에 맞게 조정하고, 모델의 잠재력을 더욱 발휘할 수 있도록 후속 훈련을 진행했습니다. 후속 훈련 단계에서는 DeepSeek-R1 시리즈 모델에서 추론 능력을 증류했으며, 모델 정확도 사이의 균형을 신중하게 유지했습니다.
우리는 DeepSeek-V3를 포괄적인 벤치마크에서 평가했습니다. 경제적인 훈련 비용에도 불구하고, 포괄적인 평가 결과 DeepSeek-V3-Base는 현재 사용 가능한 가장 강력한 오픈소스 기본 모델로 등장했으며, 특히 코드와 수학에서 뛰어난 성능을 보였습니다. 그 채팅 버전은 다른 오픈소스 모델들을 능가하며, GPT-4o와 Claude-3.5-Sonnet을 포함한 주요 폐쇄형 모델들과 동등한 성능을 보이며, 표준 벤치마크와 개방형 벤치마크에서 우수한 성과를 달성했습니다.
마지막으로, DeepSeek-V3의 경제적인 훈련 비용을 다시 한번 강조합니다. 이 비용은 알고리즘, 프레임워크, 하드웨어의 최적화된 공동 설계를 통해 달성된 결과입니다.
프리트레이닝 단계 동안, DeepSeek-V3를 각 조 단위 토큰에서 훈련하는 데에는 단 180K H800 GPU 시간이 필요합니다. 즉, 2048개의 H800 GPU가 있는 클러스터에서 3.7일이 소요됩니다. 그 결과, 우리의 프리트레이닝은 두 달 이내에 완료되며, 총 2664K GPU 시간이 소요됩니다. 이와 함께 컨텍스트 길이 확장에 119K GPU 시간, 후속 훈련에 5K GPU 시간이 소요됩니다. DeepSeek-V3의 전체 훈련 비용은 총 2.788M GPU 시간이 소요됩니다. H800 GPU의 대여 비용이 시간당 $2일 경우, 전체 훈련 비용은 단 $5.576M에 불과합니다. 앞서 언급된 비용은 DeepSeek-V3의 공식 훈련 비용만 포함하며, 아키텍처, 알고리즘 또는 데이터에 대한 이전 연구 및 실험에 소요된 비용은 제외됩니다.
우리의 주요 기여는 다음과 같습니다:
아키텍처: 혁신적인 로드 밸런싱 전략 및 훈련 목표
• DeepSeek-V2의 효율적인 아키텍처 위에, 우리는 보조 손실 없는 로드 밸런싱 전략을 선도적으로 도입하여, 로드 밸런싱을 유도할 때 발생하는 성능 저하를 최소화했습니다.
• 우리는 다중 토큰 예측(Multi-Token Prediction, MTP) 목표를 연구하고, 이것이 모델 성능에 유익함을 증명했습니다. 이 목표는 또한 추론 가속화를 위한 추측적 디코딩(speculative decoding)에도 사용될 수 있습니다.
프리트레이닝: 궁극적인 훈련 효율성을 향해
• 우리는 FP8 혼합 정밀 훈련 프레임워크를 설계하고, 처음으로 대형 모델에 대해 FP8 훈련의 실행 가능성과 효과성을 검증했습니다.
• 알고리즘, 프레임워크 및 하드웨어의 공동 설계를 통해, 우리는 노드 간 MoE 훈련에서의 통신 병목 현상을 극복하고, 거의 전면적인 계산-통신 겹침을 달성했습니다. 이는 훈련 효율성을 크게 향상시키고 훈련 비용을 줄여, 모델 크기를 추가 비용 없이 확장할 수 있게 했습니다.
• 2.664M H800 GPU 시간이라는 경제적인 비용으로, 우리는 14.8T 토큰에서 DeepSeek-V3의 프리트레이닝을 완료하고, 현재 가장 강력한 오픈소스 기본 모델을 생성했습니다. 프리트레이닝 이후의 훈련 단계는 0.1M GPU 시간만 필요합니다.
후속 훈련: DeepSeek-R1에서의 지식 증류
• 우리는 Long Chain-of-Thought (CoT) 모델, 특히 DeepSeek R1 시리즈 모델 중 하나에서 표준 LLM으로, 특히 DeepSeek-V3로 추론 능력을 증류하는 혁신적인 방법론을 소개합니다. 우리의 파이프라인은 R1의 검증 및 반영 패턴을 DeepSeek-V3에 우아하게 통합하며, 그 추론 성능을 눈에 띄게 향상시킵니다. 동시에, 우리는 DeepSeek-V3의 출력 스타일과 길이를 제어할 수 있습니다.
핵심 평가 결과 요약
• 지식:
(1) MMLU, MMLU-Pro, GPQA와 같은 교육 벤치마크에서, DeepSeek-V3는 모든 다른 오픈소스 모델을 능가하며, MMLU에서 88.5, MMLU-Pro에서 75.9, GPQA에서 59.1을 기록했습니다. 그 성능은 GPT-4o와 Claude-Sonnet-3.5와 같은 주요 폐쇄형 모델과 비교할 수 있으며, 이 분야에서 오픈소스와 폐쇄형 모델 간의 격차를 좁혔습니다.
(2) 사실성 벤치마크에서는 DeepSeek-V3가 SimpleQA와 Chinese SimpleQA에서 오픈소스 모델들 중에서 우수한 성능을 보입니다. 영어 사실성 지식(SimpleQA)에서는 GPT-4o와 Claude-Sonnet-3.5에 뒤처지지만, 중국어 사실성 지식(Chinese SimpleQA)에서는 이 모델들을 능가하며, 중국어 사실성 지식에서의 강점을 강조합니다.
• 코드, 수학, 추론:
(1) DeepSeek-V3는 모든 비-Long-CoT 오픈소스 및 폐쇄형 모델 중에서 수학 관련 벤치마크에서 최첨단 성능을 기록합니다. 특히 MATH-500과 같은 특정 벤치마크에서 o1-preview보다 더 나은 성능을 보여주며, 그 수학적 추론 능력을 입증했습니다.
(2) 코딩 관련 작업에서는 DeepSeek-V3가 LiveCodeBench와 같은 코딩 경쟁 벤치마크에서 최고의 성능을 보이며, 이 분야에서 선도적인 모델로 자리잡았습니다. 엔지니어링 관련 작업에서는 DeepSeek-V3가 Claude-Sonnet-3.5보다 약간 뒤처지지만, 여전히 다른 모든 모델들보다 현저히 앞서며 다양한 기술 벤치마크에서 경쟁력을 입증했습니다.
논문의 나머지 부분에서는 다음과 같은 내용을 다룹니다:
우리는 먼저 DeepSeek-V3 모델 아키텍처를 자세히 설명합니다 (2절). 그 후, 우리의 인프라를 소개하며, 이는 컴퓨터 클러스터, 훈련 프레임워크, FP8 훈련 지원, 추론 배포 전략, 그리고 향후 하드웨어 설계에 대한 제안을 포함합니다. 다음으로 훈련 데이터 구축, 하이퍼파라미터 설정, 긴 컨텍스트 확장 기법, 관련 평가 및 일부 논의 등을 포함한 프리트레이닝 과정을 설명합니다 (4절). 이후, 후속 훈련에 관한 우리의 노력(감독된 미세 조정(SFT), 강화 학습(RL), 해당 평가 및 논의)을 다룹니다 (5절). 마지막으로, 본 작업을 결론짓고 DeepSeek-V3의 기존 한계점과 향후 연구 방향을 제시합니다 (6절).
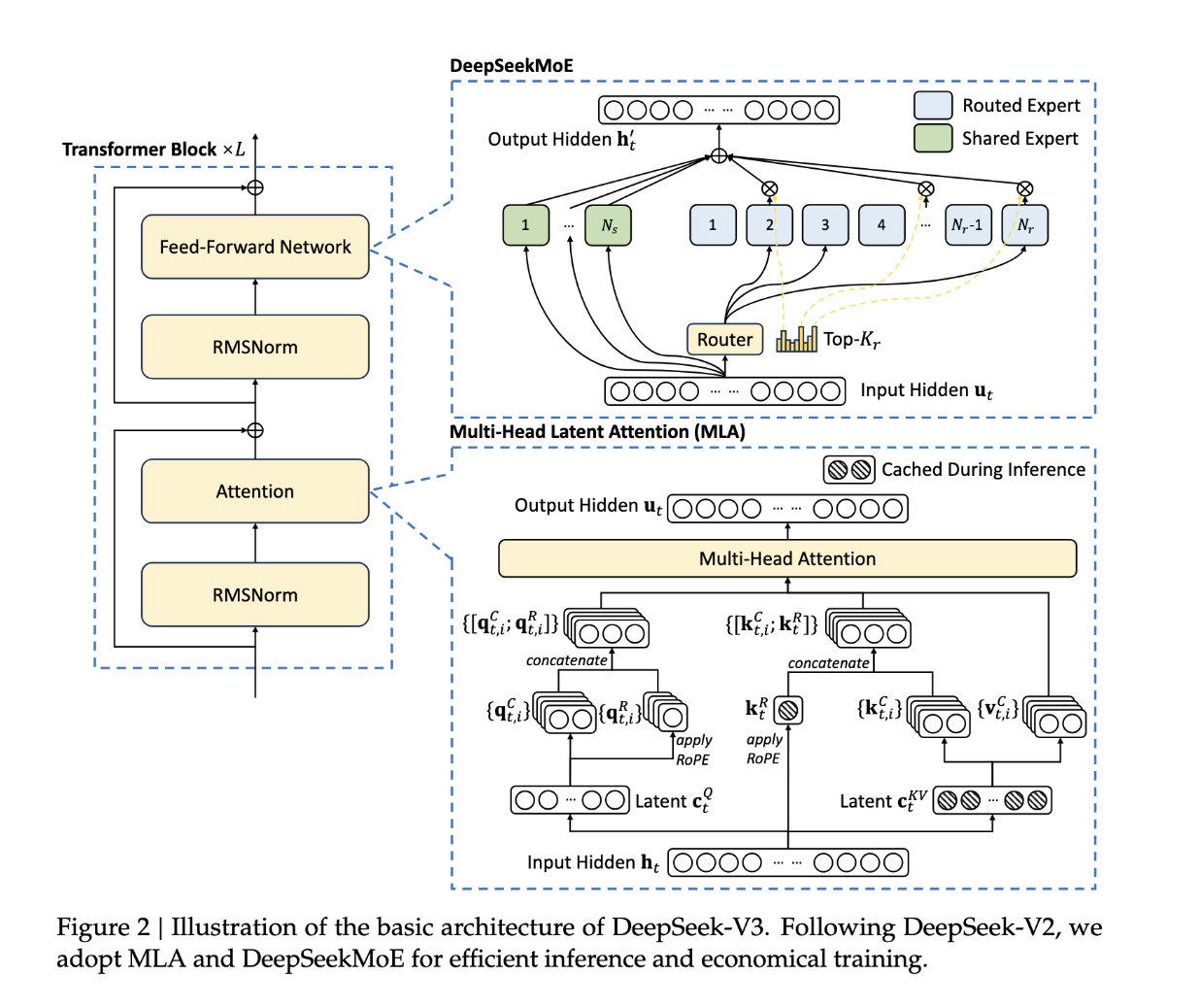
2. 아키텍처
우리는 먼저 DeepSeek-V3의 기본 아키텍처를 소개하며, 이는 효율적인 추론을 위한 다중 헤드 잠재 주의(Multi-head Latent Attention, MLA) (DeepSeek-AI, 2024c)와 경제적인 훈련을 위한 DeepSeekMoE (Dai et al., 2024)를 특징으로 합니다. 그 후, 평가 벤치마크에서 전체 성능을 향상시킨다고 관찰된 다중 토큰 예측(Multi-Token Prediction, MTP) 훈련 목표를 제시합니다. 다른 세부 사항들은 DeepSeek-V2 (DeepSeek-AI, 2024c)의 설정을 따릅니다.
2.1. 기본 아키텍처
DeepSeek-V3의 기본 아키텍처는 여전히 Transformer(Vaswani et al., 2017) 프레임워크 내에 속합니다. 효율적인 추론과 경제적인 훈련을 위해 DeepSeek-V3는 MLA(다중 헤드 잠재 주의)와 DeepSeekMoE를 채택하고 있으며, 이들은 DeepSeek-V2에서 철저히 검증되었습니다. DeepSeek-V2와 비교했을 때, 한 가지 예외는 DeepSeekMoE에 대해 보조 손실 없는 부하 균형 전략(Wang et al., 2024a)을 추가하여 부하 균형을 보장하려는 노력에서 유발될 수 있는 성능 저하를 완화한 점입니다. 그림 2는 DeepSeek-V3의 기본 아키텍처를 보여주며, 이 섹션에서는 MLA와 DeepSeekMoE의 세부 사항을 간략히 살펴보겠습니다.
...
그리고 MTP 구현에 대한 자세한 설명이 기재되어 있다. 자세한건 다음 글에
Reference
https://huggingface.co/spaces/deepseek-ai/Janus-Pro-7B
'_Project > DeepSeek_블로그자동화' 카테고리의 다른 글
| [DeepSeek 블로그자동화 프로젝트] 💻 딥시크 로컬 설치 및 프로젝트 세팅 #3 (0) | 2025.02.04 |
|---|---|
| [DeepSeek 블로그자동화 프로젝트] MVP 및 기획 이유 초안 작성 #1 (0) | 2025.02.03 |