2025. 2. 4. 00:01ㆍ_Project/DeepSeek_블로그자동화
2025.02.04
3. 💻 AI 모델 세팅 도전기

본격적인 프로젝트 세팅에 앞서서 깃허브의 6. How to Run Locally를 읽어보면 DeepSeek-V3은 Mac이랑 Window가 아닌 Linux에서만 작동해요. Oillama를 설치해서 AI모델을 효율적으로 관리해봐요.
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/README.md#6-how-to-run-locally
DeepSeek-V3/README.md at main · deepseek-ai/DeepSeek-V3
Contribute to deepseek-ai/DeepSeek-V3 development by creating an account on GitHub.
github.com


다운로드 받아주고 설치까지 완료하면 terminal 혹은 cmd 창을 켜서 아래 코드를 입력해서 설치를 확인해요.
ollama -v
다시 ollama 페이지로 돌아가 model 에 deepseek라고 검색하면 해당 모델이 검색되며 여러 모델을 선택하여 설치가능해요.

✅ Distilled 모델이란?
DeepSeek 팀은 큰 AI 모델이 학습한 추론 패턴(reasoning patterns) 을 작은 모델에 적용하는 기술을 개발했어요. 이렇게 하면 작은 모델도 원래보다 더 뛰어난 성능을 발휘할 수 있어요.
보통 작은 모델은 RL(강화학습) 같은 방법을 사용해 독자적으로 학습하지만, 이 방식은 큰 모델이 이미 배운 논리적인 사고방식을 그대로 따라가지는 못해요. 그래서 DeepSeek 팀은 큰 모델이 학습한 방식을 작은 모델에 "증류(distillation)" 해서 적용하는 방법을 연구했어요.
✅ 어떻게 학습했을까?
DeepSeek 팀은 DeepSeek-R1이라는 모델을 사용해 다양한 추론 데이터(reasoning data) 를 생성했어요. 그런 다음, 이 데이터를 활용해 여러 연구용 대형 모델들을 미세 조정(fine-tuning)하면서 작은 모델을 학습시켰어요.
이렇게 학습된 모델들은 기존의 작은 모델보다 훨씬 더 좋은 성능 을 보였어요. 즉, 큰 모델의 논리적 사고방식을 작은 모델에 그대로 녹여내서 더 뛰어난 결과를 만든 거예요.
왜 중요할까?
작은 모델도 강력한 성능
→ 기존에는 큰 모델만 가능했던 수준의 논리적 사고를 작은 모델에서도 구현 가능해요.
학습 효율 향상
→ RL 방식보다 더 빠르고 효과적으로 작은 모델을 개선할 수 있어요.
다양한 활용 가능→ 리소스가 적은 환경에서도 강력한 AI 모델을 사용할 수 있어요.
이 기술을 활용하면 작은 모델로도 복잡한 문제를 해결할 수 있어서, 앞으로 AI 연구나 개발에서 더 널리 활용될 가능성이 커요! 🚀

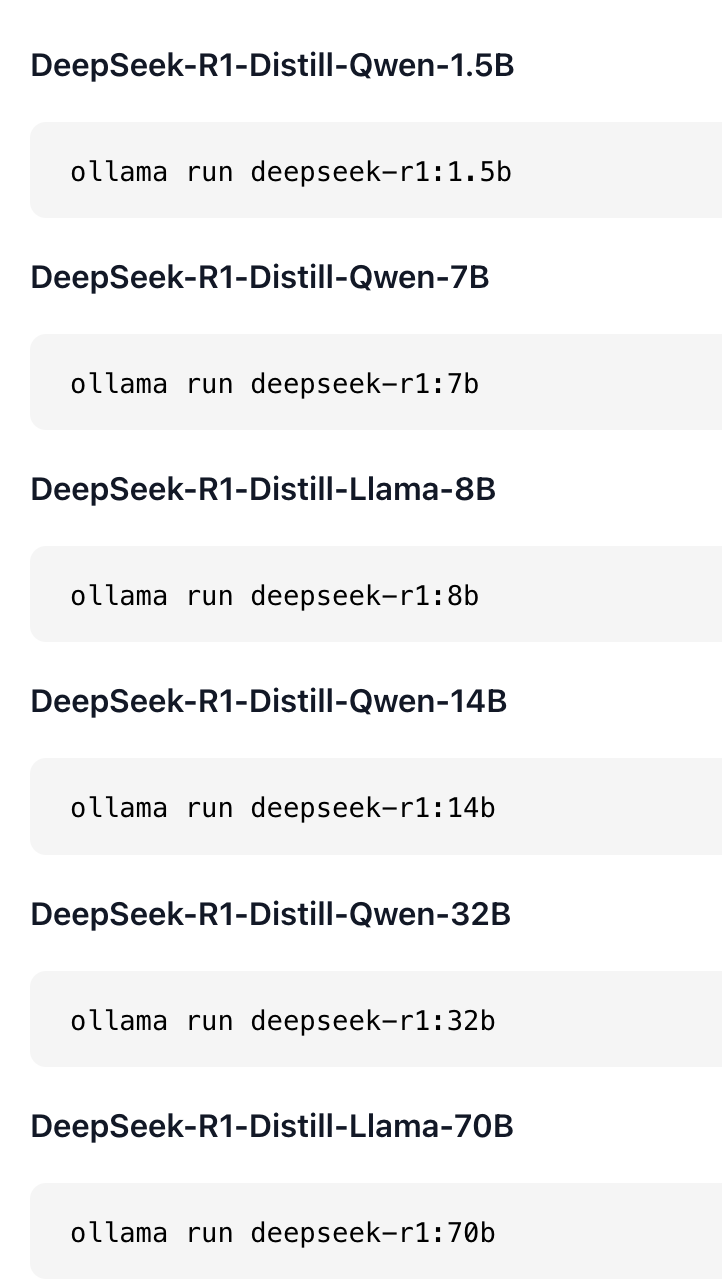
b는 모델 크기로 5B ~ 671B 다양한 파라미터로 설치할 수 있어요, GPU를 고려해서 설치해요. 저는 M2 Macbook Pro RAM 32GB 라서 아래 모델중 가장 작은 모델을 설치해봤어요. ollama run deepseek-r1:8b 를 실행하려면 DeepSeek-R1 Distill Llama 8B(80억 파라미터) 모델을 처리할 수 있는 적절한 하드웨어가 필요해요. GPU (최소 VRAM 24GB 필요)
> 무리하게 설치시 시스템이 멈출 수 있어요
✅ 최소 요구 사양
DeepSeek-R1 8B 모델은 32B 모델보다 훨씬 가벼워서, 최신 고성능 GPU 1개만 있어도 실행이 가능해요. ollama run deepseek-r1:1.5b 는 15억 파라미터로 노트북에도 실행가능한 모델이에요.
ollama run deepseek-r1:1.5b
ollama run deepseek-r1:7b
ollama run deepseek-r1:8b
📌 1.5b 결론
✅ 맥북 (M1/M2/M3)에서도 실행 가능!
✅ CPU만으로도 실행 가능하지만, GPU가 있으면 더 빠름
✅ 노트북에서도 충분히 돌릴 수 있는 가벼운 모델
🔥 최적의 환경 추천:
💻 MacBook Pro M1/M2/M3 or Windows 노트북 (i7 + 16GB RAM + SSD)
👉 이 정도면 원활하게 DeepSeek-R1 1.5B 모델을 실행할 수 있어요! 🚀
📌 7b 결론
✅ RTX 4080 (16GB) 이상이면 실행 가능, RTX 4090 (24GB) 추천!
✅ RAM은 최소 16GB, SSD는 NVMe 512GB 이상 필요
❌ 맥북에서는 실행 어려움 M2 Pro 32GB라면 실행은 가능할 수도 있지만, 매우 느리거나 충돌할 가능성이 높음
🔥 최적의 로컬 사양:
💻 RTX 4090 + 32GB RAM + i9 13900K + NVMe SSD 1TB 이상
👉 이 정도면 원활하게 DeepSeek-R1 7B 모델을 실행할 수 있어요! 🚀
📌 8b 결론
✅ RTX 4090 (24GB VRAM) 이상이면 실행 가능!
✅ RAM은 최소 32GB, SSD는 NVMe 1TB 이상 필요
❌ 맥북에서는 실행 불가능 (M 시리즈는 Ollama에서 지원 안 함)
🔥 최적의 로컬 사양:
💻 RTX 4090 + 64GB RAM + i9 13900K + NVMe SSD 1TB 이상
👉 이 정도면 원활하게 DeepSeek-R1 8B 모델을 실행할 수 있어요! 🚀
🚀 대체 방법 (클라우드 실행)
만약 로컬에서 실행이 어렵다면, 다음과 같은 클라우드 서비스를 사용할 수 있어요:
- Lambda Labs – RTX 4090 / A100 서버 제공
- Google Cloud (GCP) – A100/H100 인스턴스 사용 가능
- AWS EC2 – p4d (A100) or p5 (H100) 인스턴스 활용
✅ 딥시크를 실행해보자

이제 명령어 칸에 입력을하면 자동으로 답문이 출력되지만 웹에 연결이 되진 않아요 ! 아쉽게도 아직 한국어를,,, 하지 못하는 것 같아서 차기 프로젝트에 문제가 우려되네요. 한국어가 능숙한 다른 AI 모델도 고려해봐야겠어요.
Deep Seek Web
https://chat.deepseek.com/sign_in
서울 과기대 한국어생성 AI Bllossom/llama-3-Korean-Bllossom-70B
https://devmeta.tistory.com/80
Macbook 32GB에도 가능한 한국어 AI mistralai/Mistral-Small-24B-Instruct-2501
https://huggingface.co/mistralai/Mistral-Small-24B-Instruct-2501
한국어 제일 잘하는 AI 찾기 (feat. ollama / quantize)
최근 llama3 기반으로 한국어 모델을 활용하는 스터디 중이었는데 오늘 기가막힌 뉴스가 나왔다. 서울과기대 연구실에서 한국어를 잘 학습 시켜주셔서 모델을 올려주셨네. 너무 감사합니다~!!
devmeta.tistory.com
Reference
Hugging Face 에서 Model weight 다운로드하기
https://huggingface.co/deepseek-ai/DeepSeek-V3-Base
https://github.com/sgl-project/sglang/tree/main/benchmark/deepseek_v3
'_Project > DeepSeek_블로그자동화' 카테고리의 다른 글
| [DeepSeek 블로그자동화 프로젝트] 프로젝트 세팅을 위한 서칭과 딥시크 논문 #2 (1) | 2025.02.03 |
|---|---|
| [DeepSeek 블로그자동화 프로젝트] MVP 및 기획 이유 초안 작성 #1 (0) | 2025.02.03 |